Si estás aquí, probablemente te encuentras en uno de estos dos momentos: o acabas de vivir un incidente en producción que te ha dejado claro que algo tiene que cambiar, o llevas tiempo con la sensación de que estás volando a ciegas sobre tus bases de datos. En cualquiera de los dos casos, has llegado a la conclusión de que necesitas una herramienta de monitorización de bases de datos, y ahora tienes que decidir cuál.
El problema es que el mercado está lleno de opciones, y no todas valen lo mismo. Algunas son muy potentes pero diseñadas para entornos enterprise con presupuestos desorbitados. Otras parecen baratas hasta que intentas configurarlas. Y muchas prometen mucho en la demo y luego en producción te das cuenta de que les falta lo que más necesitas.
7 criterios para elegir una herramienta de monitorización de bases de datos
1. Datos en tiempo real con histórico
Este es el criterio más importante y el que más se pasa por alto.
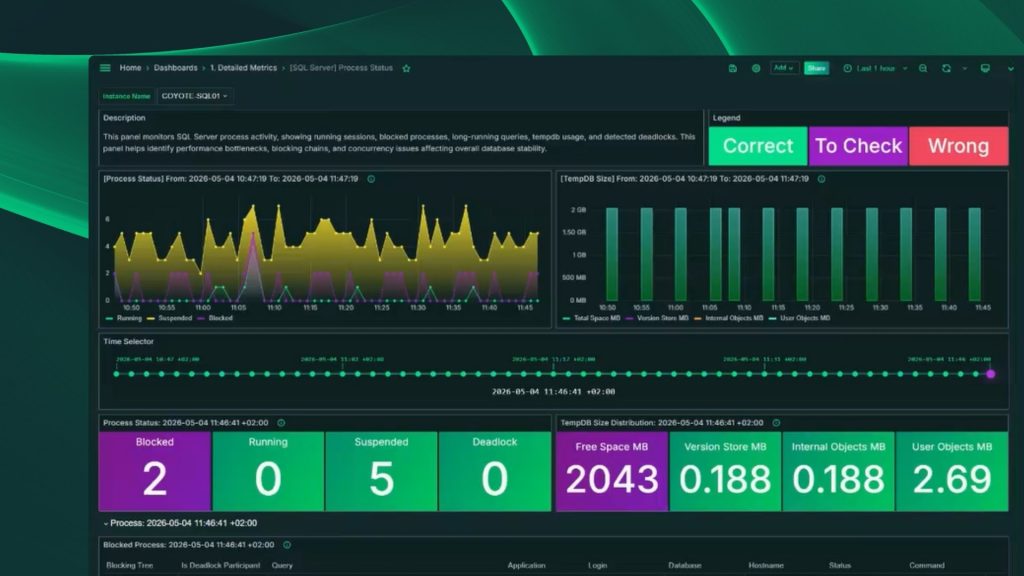
Monitorizar en tiempo real significa ver lo que está pasando ahora: queries en ejecución, bloqueos activos, uso de CPU y memoria. Eso cualquier herramienta mínimamente decente lo hace. El diferencial está en si esa herramienta también almacena histórico.
¿Por qué importa el histórico? Porque los incidentes más graves no siempre ocurren cuando estás delante del servidor. El bloqueo que tumbó la aplicación a las 3 de la mañana, la query que saturó la CPU el martes pasado justo antes de que empezaran las quejas de los usuarios, el crecimiento de una tabla que lleva meses acelerándose… nada de eso lo puedes ver en el momento en que llegas a investigar. Ya pasó.
Una herramienta que solo te muestre el estado actual es útil. Una que también te guarde el histórico de procesos, bloqueos, contadores de rendimiento y crecimiento es indispensable.
2. Cobertura real de tu entorno
Aquí hay un detalle que muchas herramientas no resuelven bien: no todas las organizaciones tienen un entorno homogéneo. Cada vez más equipos gestionan entornos mixtos, con bases de datos on-premises y en la nube conviviendo.
Una herramienta que cubre bien el on-premises pero te deja ciego en la nube no es una solución completa. Y al revés: herramientas pensadas solo para entornos cloud que no te cubren las instancias on-premises que sigues teniendo.
3. Alertas proactivas, no reactivas
Hay una diferencia enorme entre enterarte de un problema cuando te llama un usuario y enterarte cuando la herramienta te avisa con antelación suficiente para actuar.
Una herramienta de monitorización de bases de datos que no tiene alertas inteligentes te obliga a estar pendiente del dashboard. Eso no escala. Lo que necesitas es que la herramienta detecte anomalías, supere umbrales configurables o identifique tendencias peligrosas, y te lo comunique antes de que el problema impacte en producción.
Las alertas deben ser configurables (no vale con alertas genéricas que no puedes ajustar a tu entorno) y deben cubrir los escenarios que realmente importan: bloqueos prolongados, queries con planes inesperados, crecimiento anómalo de bases de datos, jobs fallidos, uso de recursos al límite.
4. Impacto mínimo en el servidor monitorizado
Una herramienta de monitorización de bases de datos que ralentiza el servidor que está monitorizando es como un médico que hace enfermar a sus pacientes. Suena obvio, pero es un problema real que ocurre con herramientas que hacen polling agresivo o ejecutan consultas pesadas para recopilar métricas.
Antes de desplegar cualquier herramienta en producción, pregunta cómo recopila datos, con qué frecuencia y qué impacto tiene en los recursos del servidor. Si no te dan una respuesta concreta y verificable, desconfía.
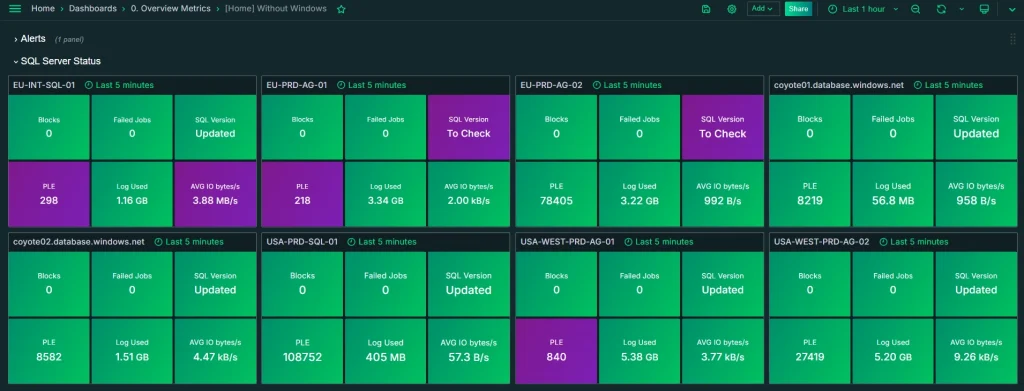
5. Visibilidad del estado global, no solo servidor a servidor
Si gestionas más de una instancia o base de datos (y si tienes más de dos, probablemente gestionas más de cinco), necesitas poder ver el estado general de todo tu entorno de un vistazo, no ir servidor a servidor.
Una herramienta sin una vista consolidada te obliga a multiplicar el tiempo que dedicas a hacer rondas de revisión. Y cuando ocurre un incidente, perder tiempo navegando entre paneles individuales puede ser la diferencia entre resolverlo en minutos o en horas.
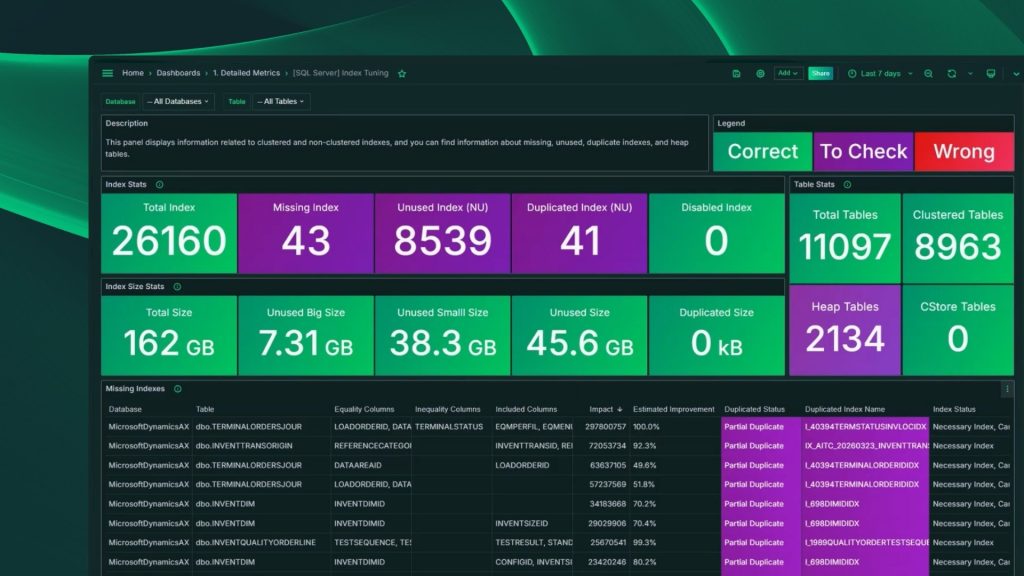
6. Evaluación de buenas prácticas y configuración
Un buen DBA sabe que la mayoría de los problemas de rendimiento tienen su origen en una mala configuración, no en el código. Parámetros mal configurados, inicialización instantánea de ficheros desactivada, autogrowth con valores ridículos, bases de datos sin backups recientes… estos problemas existen en producción más de lo que nos gustaría reconocer.
Una herramienta que evalúa tu configuración contra buenas prácticas y te avisa cuando algo no está bien te ahorra horas de auditoría manual y te ayuda a prevenir problemas antes de que ocurran.
7. Escalabilidad sin complicaciones
Una herramienta que funciona bien para 2 instancias pero que se vuelve un calvario de gestión para 10 no es escalable. A medida que tu entorno crece, la herramienta debe crecer con él sin requerir una reconfiguración completa ni disparar los costes de forma desproporcionada.
El modelo de licencias también importa. ¿Pagas por instancia, por número de bases de datos, por usuario? ¿El precio escala de forma razonable? ¿Puedes empezar con poco e ir ampliando sin fricciones?
Por qué los scripts no son suficientes para monitorizar tus bases de datos
Antes de cerrar con una recomendación, vale la pena ser honesto sobre la alternativa más común: los scripts propios y las DMVs.
Los scripts son útiles y gratuitos, y en este blog publicamos muchos. Pero tienen limitaciones objetivas:
- No guardan histórico. Cuando llegas a investigar, el bloqueo ya pasó.
- No tienen alertas. Te enteras del problema cuando te llama alguien.
- No escalan. Ejecutar scripts manualmente en 10 o 20 instancias no es viable.
- Requieren conocimiento avanzado. No todos los miembros del equipo saben interpretar los resultados correctamente.
- No tienen vista global. Cada script te da información de una instancia a la vez.
Para un DBA experimentado gestionando una o dos instancias con tiempo para hacerlo, los scripts funcionan. Para equipos que gestionan entornos más amplios o que necesitan capacidad de reacción proactiva, no son suficientes.
Coyote Monitor: la herramienta de monitorización de bases de datos para tu equipo
Coyote Monitor es la herramienta de monitorización de bases de datos que hemos desarrollado en Aleson ITC con exactamente estos criterios en mente.
Cubre SQL Server on-premises, Azure SQL Database y Azure SQL Managed Instance de forma nativa. Almacena histórico de procesos, bloqueos, contadores de rendimiento y crecimiento de bases de datos y tablas, para que puedas investigar qué pasó, no solo qué está pasando. Tiene alertas inteligentes configurables, un panel de best practices que evalúa tu configuración automáticamente, y una vista global del estado de todas tus instancias. Todo con un impacto mínimo en los servidores monitorizados.
Si gestionas bases de datos en producción y quieres dejar de apagar fuegos para empezar a prevenirlos, Coyote Monitor está diseñado para ti.
Preguntas frecuentes sobre herramientas de monitorización de bases de datos
Si estás en proceso de evaluar herramientas, estas son las preguntas que deberías hacerle a cualquier proveedor. Te damos también las respuestas de Coyote Monitor para que tengas un punto de referencia concreto.
¿Cuántos días de histórico almacena la herramienta?
Coyote Monitor almacena histórico de procesos, bloqueos, contadores de rendimiento y crecimiento de bases de datos y tablas. El período de retención es configurable según las necesidades de tu entorno, por lo que no estás limitado a una ventana fija de horas o días.
¿Cubre entornos on-premises y cloud de forma nativa?
Sí. Coyote Monitor cubre SQL Server on-premises, Azure SQL Database y Azure SQL Managed Instance de forma nativa. Cada plataforma tiene sus paneles y métricas adaptados a sus particularidades.
¿Las alertas son configurables o solo hay umbrales genéricos?
Las alertas de Coyote Monitor son configurables para adaptarse a las condiciones reales de tu entorno. No tiene sentido alertar por el mismo umbral de CPU en un servidor de reporting y en uno de OLTP crítico.
¿Cuál es el impacto de la herramienta en los servidores monitorizados?
Coyote Monitor está diseñado con impacto mínimo como requisito, no como característica opcional. La recopilación de métricas está pensada para no interferir con la carga de trabajo de producción.
¿Hay una vista global que muestre el estado de todas las bases de datos a la vez?
Sí. El panel de resumen de estado de servidores te da visibilidad consolidada de todo tu entorno sin tener que navegar instancia a instancia. Es uno de los primeros paneles que ven los equipos que gestionan múltiples servidores.
¿La herramienta evalúa la configuración contra buenas prácticas?
Coyote Monitor incluye un panel de Best Practices que revisa automáticamente la configuración de cada instancia y señala los puntos de mejora. No es una lista estática: está pensada para entornos en producción real.
¿El modelo de precios escala de forma razonable si el entorno crece?
El precio de Coyote Monitor es por instancia o base de datos, con facturación anual o mensual. Puedes empezar con una instancia en la prueba gratuita de 30 días y escalar sin sorpresas. Los precios están publicados en coyotemonitor.com/precios/.
Empieza a monitorizar hoy
Puedes probar Coyote Monitor gratis durante 30 días, sin tarjeta de crédito, con una instancia o base de datos de tu entorno.
Si prefieres ver primero cómo funciona aplicado a un entorno como el tuyo, puedes solicitar una demo con nuestro equipo.