SQL Server registra cada vez que el optimizador echa en falta un índice para resolver una query de forma eficiente. Esa información se acumula en las DMVs de missing indexes y consultarla es el primer paso para mejorar el rendimiento. Pero crear índices a ciegas basándote solo en las DMVs es un error que puede costarte más rendimiento del que ganas. En este post te enseño a consultar esas DMVs y a analizar cada recomendación antes de actuar. Vamos al lío.
¿Qué son los índices faltantes y qué DMVs los registran?
Los índices faltantes son recomendaciones que genera el optimizador cada vez que detecta que un índice podría haber reducido el coste de una query. SQL Server no los crea automáticamente — los registra en estas DMVs para que tú los evalúes:
| DMV | ¿Qué contiene? |
|---|---|
sys.dm_db_missing_index_details | Detalle del índice: tabla, columnas de equality, inequality e INCLUDE |
sys.dm_db_missing_index_groups | Relación entre grupos y detalles (tabla puente) |
sys.dm_db_missing_index_group_stats | Estadísticas: seeks, scans, coste medio, impacto estimado |
sys.dm_db_missing_index_group_stats_query | (SQL Server 2019+) Enlaza cada recomendación con la query que la originó |
Las equality_columns son columnas en predicados de igualdad (WHERE col = valor) y las inequality_columns en predicados de rango (>, <, BETWEEN). Al crear el índice, las de equality van primero en la clave, seguidas de las inequality — este orden permite un seek eficiente.
Script para obtener los índices faltantes con su impacto estimado
Este script combina las tres DMVs principales y ordena por improvement_measure — un cálculo que combina coste, impacto y frecuencia de uso.
SELECT TOP 50
GETDATE() AS fecha_consulta,
DB_NAME(mid.database_id) AS base_datos,
mid.statement AS tabla,
CONVERT(DECIMAL(28,1),
migs.avg_total_user_cost
* migs.avg_user_impact
* (migs.user_seeks + migs.user_scans)
) AS improvement_measure,
migs.avg_user_impact AS impacto_estimado_pct,
migs.user_seeks,
migs.user_scans,
mid.equality_columns AS columnas_equality,
mid.inequality_columns AS columnas_inequality,
mid.included_columns AS columnas_include,
'CREATE NONCLUSTERED INDEX [IX_'
+ REPLACE(REPLACE(REPLACE(mid.statement, '[', ''), ']', ''), '.', '_')
+ '_' + CONVERT(VARCHAR, mid.index_handle) + '] ON '
+ mid.statement + ' ('
+ ISNULL(mid.equality_columns, '')
+ CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ', '
ELSE ''
END
+ ISNULL(mid.inequality_columns, '')
+ ')'
+ ISNULL(' INCLUDE (' + mid.included_columns + ')', '')
AS script_creacion
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY improvement_measure DESC;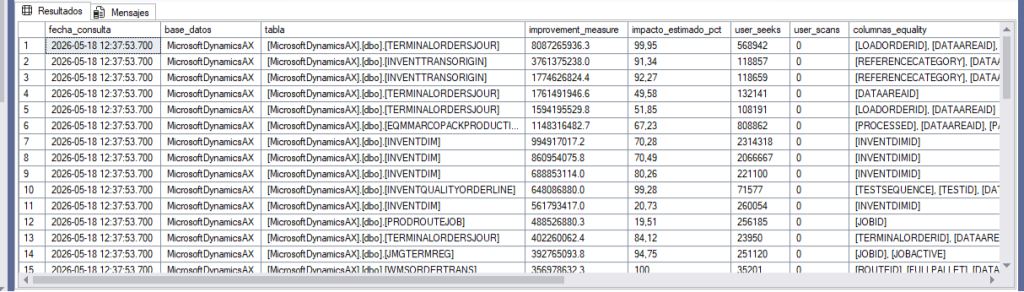
Pero ojo — no copies y pegues esos scripts de creación directamente. Antes hay que analizar cada uno.
Script para obtener la query que originó la recomendación (SQL Server 2019+)
Desde SQL Server 2019, puedes saber exactamente qué query generó cada recomendación. Sin este contexto, estás decidiendo a ciegas: ¿es una query que se ejecuta miles de veces al día o algo que alguien lanzó una vez manualmente?
SELECT TOP 30
mid.statement AS tabla,
CONVERT(DECIMAL(28,1),
migs.avg_total_user_cost
* migs.avg_user_impact
* (migs.user_seeks + migs.user_scans)
) AS improvement_measure,
migs.avg_user_impact AS impacto_pct,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
st.text AS query_origen
FROM sys.dm_db_missing_index_group_stats_query AS migsq
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migsq.group_handle = migs.group_handle
INNER JOIN sys.dm_db_missing_index_groups AS mig
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
CROSS APPLY sys.dm_exec_sql_text(migsq.last_sql_handle) AS st
WHERE mid.database_id = DB_ID()
ORDER BY improvement_measure DESC;¿Por qué no deberías crear todos los índices que recomienda SQL Server?
Las DMVs son una herramienta de diagnóstico, no un plan de acción automático. Hay varias razones para analizar cada recomendación individualmente:
El índice puede ser un duplicado total o parcial. SQL Server no compara las recomendaciones contra los índices que ya tienes. Puede recomendarte (ColA, ColB) cuando ya tienes (ColA, ColB, ColC) que cubre esa query. Lo mismo aplica a solapamientos: un índice en (ColA, ColB) INCLUDE (ColC) puede estar cubierto por (ColA, ColB) INCLUDE (ColC, ColD). Si lo creas sin verificar, tendrás un índice redundante que consume espacio y penaliza cada escritura.
La tabla puede estar sobreindexada. Cada índice no clúster tiene un coste en INSERTs, UPDATEs y DELETEs. He visto tablas con 25 índices donde las escrituras tardaban el triple. Cuando superas los 8-10 índices no clúster, revisa sys.dm_db_index_usage_stats — busca índices con cero seeks y scans pero muchos updates.
Las columnas pueden no estar en el orden óptimo. Las DMVs ordenan las columnas según aparecieron en la query, no por selectividad. Revisa la distribución de valores de cada columna para determinar el orden correcto de la clave.
Pierdes todo con cada reinicio. Toda la información de missing indexes se pierde cuando se reinicia SQL Server. No se persiste en disco. Comprueba cuánto tiempo lleva arrancado tu servidor antes de tomar decisiones:
SELECT sqlserver_start_time FROM sys.dm_os_sys_info;
Verificar duplicados y generar el script de creación correcto
Antes de crear cualquier índice, compara con los que ya existen en esa tabla:
DECLARE @esquema SYSNAME = 'dbo';
DECLARE @tabla SYSNAME = 'TuTabla';
SELECT
i.name AS nombre_indice,
i.type_desc AS tipo,
STRING_AGG(
CASE WHEN ic.is_included_column = 0
THEN c.name + CASE WHEN ic.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END
END, ', '
) WITHIN GROUP (ORDER BY ic.key_ordinal) AS columnas_clave,
STRING_AGG(
CASE WHEN ic.is_included_column = 1 THEN c.name END, ', '
) AS columnas_include
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
INNER JOIN sys.columns AS c
ON ic.object_id = c.object_id AND ic.column_id = c.column_id
WHERE i.object_id = OBJECT_ID(@esquema + '.' + @tabla)
AND i.type IN (1, 2)
GROUP BY i.name, i.type_desc;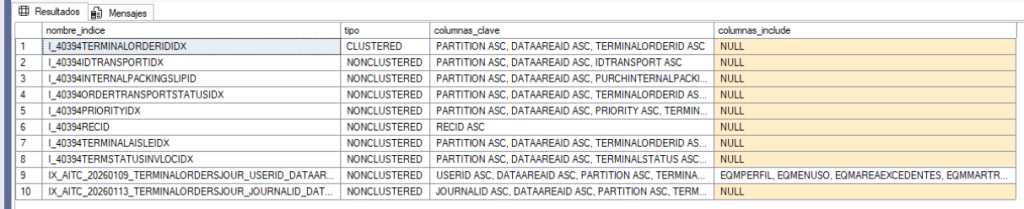
Cuando decidas que un índice merece crearse, recuerda que ONLINE = ON solo está disponible en Enterprise Edition (y Azure SQL Database / Managed Instance). En Standard Edition, la tabla se bloquea durante toda la operación.
CREATE NONCLUSTERED INDEX [IX_Pedidos_ClienteId_FechaPedido] ON [dbo].[Pedidos] ([ClienteId], [FechaPedido]) INCLUDE ([Total], [Estado]) WITH (ONLINE = ON, SORT_IN_TEMPDB = ON, MAXDOP = 4); GO -- Standard Edition CREATE NONCLUSTERED INDEX [IX_Pedidos_ClienteId_FechaPedido] ON [dbo].[Pedidos] ([ClienteId], [FechaPedido]) INCLUDE ([Total], [Estado]) WITH (SORT_IN_TEMPDB = ON, MAXDOP = 4); GO
Si no sabes qué edición tienes: SELECT SERVERPROPERTY('Edition');
Las limitaciones del enfoque manual
Todo lo anterior funciona, pero en el día a día tiene limitaciones claras: pierdes la información con cada reinicio; no detectas duplicados automáticamente — viable con 5 tablas, no con 50 bases de datos; no sabes si una tabla está sobreindexada sin cruzar varias DMVs; el script de creación no considera la edición ni añade ONLINE = ON; y si gestionas múltiples instancias, repetir el proceso en cada una es inviable.
Cómo Coyote Monitor resuelve el análisis de índices faltantes
El panel de Index Tuning de Coyote Monitor analiza automáticamente las recomendaciones de SQL Server. Compara cada índice recomendado contra los existentes y te informa si generaría un duplicado total o parcial, indicándote qué índice lo cubre. Calcula un porcentaje de mejora más interpretable que la improvement_measure cruda. Te alerta si la tabla está sobreindexada. Y genera el script de creación calculando automáticamente si puede ser ONLINE = ON o no según la edición de SQL Server. Además, al monitorizar de forma continua, la información no se pierde con los reinicios.
En lugar de ejecutar scripts manualmente y comparar entre ventanas de SSMS, tienes toda la información consolidada y lista para actuar — en todas tus instancias.
👉 Prueba Coyote Monitor gratis durante 30 días y comprueba cómo el panel de Index Tuning te ahorra horas de análisis manual.
Preguntas frecuentes sobre índices faltantes en SQL Server
¿Qué DMV uso para ver los índices faltantes en SQL Server?
Las tres DMVs principales son sys.dm_db_missing_index_details, sys.dm_db_missing_index_groups y sys.dm_db_missing_index_group_stats. Desde SQL Server 2019, también sys.dm_db_missing_index_group_stats_query para enlazar cada recomendación con la query concreta.
¿Se pierden los índices faltantes cuando se reinicia SQL Server?
Sí. Toda la información se pierde con cada reinicio. Si necesitas conservarla, crea un SQL Agent Job que guarde los datos periódicamente o usa una herramienta como Coyote Monitor que los registra de forma continua.
¿Debo crear todos los índices que recomiendan las DMVs?
No. Cada recomendación debe analizarse: verificar que no genera un duplicado, que la tabla no está sobreindexada, y que el impacto justifica el coste de mantenimiento.
¿Puedo crear índices con ONLINE = ON en Standard Edition?
No. ONLINE = ON solo está disponible en Enterprise Edition, Azure SQL Database y Azure SQL Managed Instance. En Standard Edition la tabla se bloquea durante la creación.
¿Te ha resultado útil? Si quieres dejar de pelear con scripts manuales para el tuning de índices, solicita una demo de Coyote Monitor y te enseñamos el panel de Index Tuning en acción.